我們除了可以使用Beautiful Soup中的特定屬性來幫助走訪網頁,也可以使用物件樹或上一個/下一個元素來走訪剖析HTML網頁的標籤順序。
Python物件樹走訪:
Python物件樹使以類似階層上下樓梯的方式走訪標籤。下方以FJU_p4.html左半邊內容< section class=”left” >的html格式內容為例: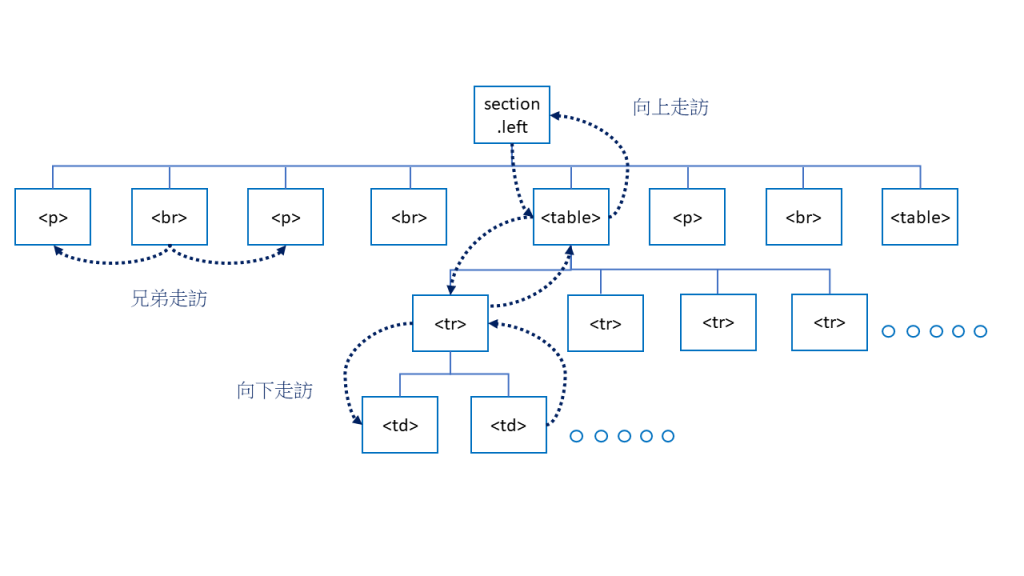
向下走訪: 從 < section.left > -> < table> -> < tr > -> < td >
向上走訪: 從 < td > -> < tr > -> < table > -> < section.left >
兄弟走訪: 即同一層的走訪。從 < p > -> < br > 和 < br > -> < p >
上一個和下一個元素走訪: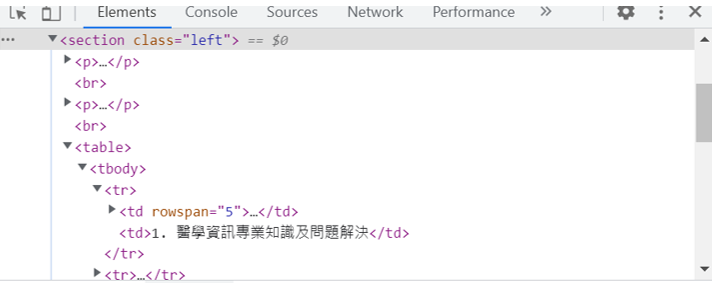
以FJU_p4.html中的左半邊內容< section class=”left” >為例擷取指定的文字或標籤內容。
向下走訪
(1) 使用子標籤名稱
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用屬性向下走訪
print(soup.html.head.title.string)
print(soup.html.head.meta["charset"])
# 使用table屬性取得第1個<td>標籤
print(soup.html.body.section.table.tr.td.string)

(2) 使用children屬性取得所有子標籤
from bs4 import BeautifulSoup
from bs4.element import NavigableString
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用屬性取得所有子標籤
tag_div = soup.select("table") # 找到<table>標籤
tag_tr = tag_div[0].tr # 走訪到之下的<tr>
for child in tag_tr.children:
if not isinstance(child, NavigableString):
print(child.name)
for tag in child:
if not isinstance(tag, NavigableString):
print(tag.name, tag.string)
else:
print(tag.replace('\n', ''))

向上走訪
(1) 走訪父標籤
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_table = soup.select("table") # 找到<table>
tag_td = tag_table[0].tr # 走訪到之下的<td>
# 使用屬性取得父標籤
print(tag_td.parent.name)

(2) 走放祖父標籤
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_table = soup.select("table") # 找到<table>標籤
tag_td = tag_table[0].tr # 走訪到之下的<td>
# 使用函數取得所有祖先標籤
for tag in tag_td.find_parents():
print(tag.name)

兄弟走訪
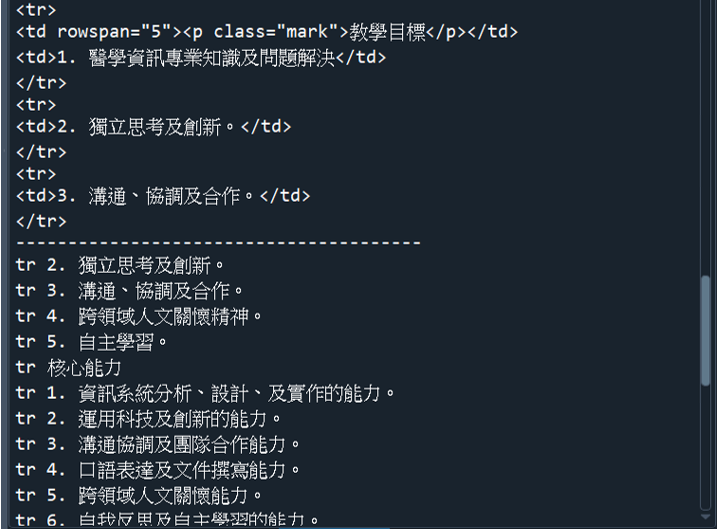
(1) 走訪下一個兄弟標籤使用next_sibling屬性和find_next_sibling()函數
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_section = soup.select(".left") # 找到class=left的標籤
first_td = tag_section[0].table.tr # 第1個<td>
print(first_td)
# 使用next_sibling屬性取得下一個兄弟標籤
second_td = first_td.next_sibling.next_sibling
print(second_td)
# 呼叫next_sibling()函數取得下一個兄弟標籤
third_td = second_td.find_next_sibling()
print(third_td)
print("---------------------------------------")
# 呼叫next_siblings()函數取得所有兄弟標籤
for tag in first_td.find_next_siblings():
print(tag.name, tag.td.string)
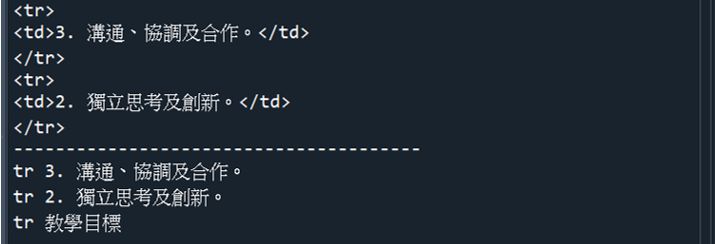
(2) 走訪上一個標籤使用previous_sibling屬性和find_previous_sibling()函數
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_section = soup.select(".left") # 找到class=left的標籤
tag_td = tag_section[0].table.tr # 第1個<td>
fifth_td =
tag_td.next_sibling.next_sibling.next_sibling.next_sibling.next_sibling.next_sibling
# 使用previous_sibling屬性取得前一個兄弟標籤
fourth_td = fifth_td.previous_sibling.previous_sibling
print(fourth_td )
# 呼叫previous_sibling()函數取得前一個兄弟標籤
third_td = fourth_td.find_previous_sibling()
print(third_td)
print("---------------------------------------")
# 呼叫previous_siblings()函數取得所有兄弟標籤
for tag in fifth_td.find_previous_siblings():
print(tag.name, tag.td.string)
下一個元素走訪:使用next_element屬性
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_section = soup.section # 找到第<section>標籤
print(type(tag_section), tag_section.name)
tag_next = tag_section.next_element.next_element # 找到第<section>標籤的下一個元素
print(type(tag_next), tag_next.name)

上一個元素走訪:使用previous_element屬性
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_tr = soup.tr # 找到第<tr>標籤
print(type(tag_tr), tag_tr.name)
tag_previous = tag_tr.previous_element.previous_element # 找到第<tr>標籤的上一個元素
print(type(tag_previous), tag_previous.name)



 iThome鐵人賽
iThome鐵人賽